Una vez vi una charla de Ryan Timpe, un Data Scientist de Lego, que en una charla en la RStudio Conference contaba cómo a veces hacía proyectos que fueran divertidos para aprender nuevos skills de análisis de datos. En su charla cuenta por ejemplo, que hizo un análisis de los diálogos de la serie The Golden Girls usando técnicas de text mining para detectar cuáles eran las palabras más frecuentes, entonces cada vez que una protagonista decía esa palabra ellos hacían un fondo blanco de lo que estuvieran tomando.
Este post va de lo mismo. Yo quería aprender a usar imágenes en mis visualizaciones, así nació este proyecto en el que usé imágenes de personas con rasgos “similares” a los míos e incluir las fotos en un gráfico de dispersión.
Esto que es una boludez implicó:
Crear un formulario en Google Forms
Levantar los datos de las respuestas
Procesar los resultados
E incluir visualizaciones usando las imágenes de las personas.
Este tipo de proyectos lo que permite es que el esfuerzo que dedicás a aprender no se sienta pesado, y que te da una motivación extra para buscar la solución para lograr el resultado.
Un poco de contexto
Este soy yo:
En mi luna de miel en Mendoza
Como verán, tengo el pelo más o menos largo, con flequillo y barba candado. Mucha gente dice que me parezco a Nicolás del Caño 🤷, un diputado del Partido de los Trabajadores Socialistas de Argentina y que tiene un corte de pelo parecido al mío y también usa barba.
Nicolás del Caño
En estas fotos no nos vemos tan parecidos, pero déjenme contarles una anécdota. Cuando mi hija tenía 3 años aproximadamente estábamos en campaña electoral de diputados y había afiches de todos los partidos políticos pegados por todos lados, incluyendo claro está los del PTS y Nicolás del Caño obviamente.
En esa época mi hija y mi esposa iban caminando por la calle, y cuando se estaban acercando a uno de los afiches de Del Caño mi hija apunta con su dedito y dice “Papá!” como si yo fuera el que estaba en el afiche. Así que algún parecido hay.
También dijo lo mismo mirando un afiche de Johnny Depp promocionando el perfume Savage, pero esa no me la cree nadie.
Otros personajes con los que mis amigos suelen bromear que somos parecidos son el Gigoló, Roberto Baradel, o el Mono Burgos.
El Gigoló
Roberto Baradel
El Mono Burgos
Ya sé lo que están pensando: Con amigos así quién necesita enemigos. Pero igual se hacen querer.
Génesis de la idea: k-nn
La idea de este análisis surgió un día después de hacer una explicación sobre un método de clustering llamado k-nn. Los métodos de clustering son técnicas de ciencia de datos que permiten hallar grupos entre los datos (llamados clusters en la jerga).
El método k-nn, knearest neighbors o de vecinos más cercanos lo que hace es asignar a cada individuo a un cluster en función de las características de sus “vecinos”. Es decir que determina a qué grupo pertenece cada caso en función a qué casos se parece más.
La forma que se me ocurrió para explicar esto de manera visual fue con este dibujo que hice en Paint:
La explicación es que yo, dentro de ese conjunto de datos, estoy más cerca de pertenecer al cluster del Mono Burgos y de Nicolás del Caño, más que del cluster de Keanu Reeves, Jeff Bridges y Brad Pitt.
Y después tuve una idea. ¿Y si hago esto con datos?
Haciendo cosas raras para gente normal en R
La idea entonces es replicar el gráfico de arriba pero usando datos. Entonces lo que hice fue en primer lugar buscar fotos de personajes argentinos e internacionales que tengan el pelo más o menos largo, usen barba, y en algunos casos tengan unos kilos de más.
Para este paso lo que hice fue pasar todas las fotos de los personas en Canva para que me queden todas las imágenes del mismo tamaño.
Luego me armé un formulario en Google Forms con cada imagen para compartir con amigas y amigos para que voten del 1 al 10 la facha (facha en Argentina es una forma de decir belleza) y la copadez (que tan agradables son las personas).
Los personajes involucrados fueron:
Nicolás del Caño
Roberto Baradel
El Mono Burgos
Ricardo Caruso Lombardi
Ben Affleck
Jeff Bridges
Brad Pitt
Javier Bardem
Keanu Reeves
Y su fiel servidor 😉
En mi análisis original cargué los datos directamente desde el Google Sheets que se genera con los resultados del Forms. Solo para los fines de reproducibilidad en este caso voy a usar un archivo csv así si quieren pueden replicar los resultados.
Así que ahora podemos armar el script.
Cargando los datos y preparándolos
Empecemos cargando las librerías y los datos directamente desde un repositorio:
# Paqueteslibrary(tidyverse) # Cargar, limpiar y preparar datoslibrary(ggimage) # Para usar imágenes en las visualizaciones# Datosclones <-read_delim("https://raw.githubusercontent.com/chechoid/silliest-use-of-r/main/source.csv", delim =";")comentarios <- clones %>%select(comentarios =`Poné lo que quieras... parecidos, chistes, comentarios, etc...`) %>%filter(!is.na(comentarios))# Exploremos los datoshead(clones)
# A tibble: 6 × 24
`Marca temporal` `Facha de Keanu` `Copadez de Keanu` `Facha de Russell`
<dttm> <dbl> <dbl> <dbl>
1 2021-06-23 12:37:28 10 10 7
2 2021-06-23 12:39:12 4 10 5
3 2021-06-23 12:42:21 8 9 8
4 2021-06-23 12:43:24 10 10 1
5 2021-06-23 12:45:03 10 8 4
6 2021-06-23 12:45:12 5 9 1
# ℹ 20 more variables: `Copadez de Russell` <dbl>, `Facha de Nico` <dbl>,
# `Copadez de Nico` <dbl>, `Facha de Roberto` <dbl>,
# `Copadez de Roberto` <dbl>, `Facha de Jeff` <dbl>, `Copadez de Jeff` <dbl>,
# `Facha de Brad` <dbl>, `Copadez de Brad` <dbl>, `Facha del Mono` <dbl>,
# `Copadez del Mono` <dbl>, `Facha de Sergio` <dbl>,
# `Copadez de Sergio` <dbl>, `Facha de Ricky` <dbl>,
# `Copadez de Ricky` <dbl>, `Facha de Ben` <dbl>, `Copadez de Ben` <dbl>, …
Ahí podemos ver que para cada personaje tenemos una columna con el puntaje de su facha y su puntaje de copadez.
El siguiente paso consiste en eliminar algunas columnas que no son relevantes para el análisis, y agregamos una columna de id. Y luego tenemos que “pivotear” la tabla para que nos queden todas las columnas de puntajes de los personajes en dos columnas:
# Eliminar columnas innecesariasclones <- clones %>%select(-`Marca temporal`, -`Poné lo que quieras... parecidos, chistes, comentarios, etc...`)# Agregar columna de idclones <- clones %>%rowid_to_column(var ="id")# Pivotear variablesclones <- clones %>%pivot_longer(cols =c("Facha de Keanu":"Copadez de Javier"),names_to ="personaje",values_to ="puntaje")# Veamos como queda el dataset ahorahead(clones)
# A tibble: 6 × 3
id personaje puntaje
<int> <chr> <dbl>
1 1 Facha de Keanu 10
2 1 Copadez de Keanu 10
3 1 Facha de Russell 7
4 1 Copadez de Russell 10
5 1 Facha de Nico 1
6 1 Copadez de Nico 1
Habíamos comenzado con un dataset de 66 filas y 24 columnas. Ahora terminamos con un data frame de 1.452 filas en 3 columnas. Ahora necesitamos eliminar las palabras intermedias de y del de los nombres en la columna personaje así después podemos crear una columna para facha, y otra para copadez.
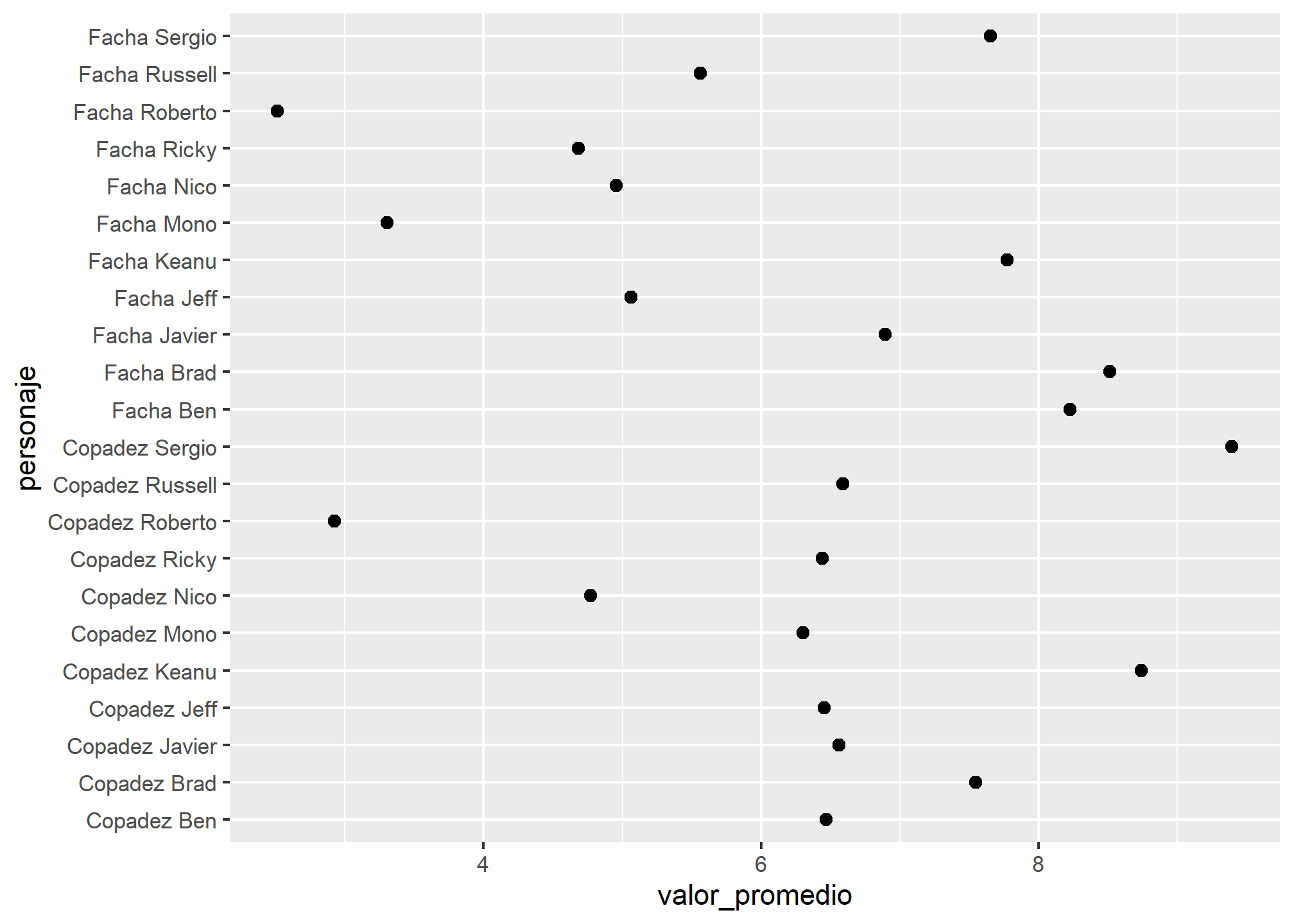
# Separar variables categóricasclones <- clones %>%mutate(personaje =str_remove(personaje, "de "),personaje =str_remove(personaje, "del "))# Veamos el puntaje promedio de cada personaje y sus caraceterísticasclones %>%group_by(personaje) %>%summarise(valor_promedio =mean(puntaje)) %>%ggplot(aes(x = valor_promedio, y = personaje)) +geom_point(size =2)
# Dividimos la columna 'personaje' en dos columnas, una para la métrica y otra para el nombreclones <- clones %>%separate(personaje, into =c("metrica", "persona"))# Pivotear ancho clones <- clones %>%pivot_wider(id_cols =c(id, persona),names_from = metrica,values_from = puntaje)# Veamos como queda el data frame ahorahead(clones)
# A tibble: 6 × 4
id persona Facha Copadez
<int> <chr> <dbl> <dbl>
1 1 Keanu 10 10
2 1 Russell 7 10
3 1 Nico 1 1
4 1 Roberto 1 1
5 1 Jeff 5 5
6 1 Brad 10 10
Luego de estos pasos quedamos con un data frame de 726 filas, una para cada votación para cada personaje, y con 4 columnas, id, persona, Facha y Copadez. Con estos datos podemos ver los resultados de cada persona:
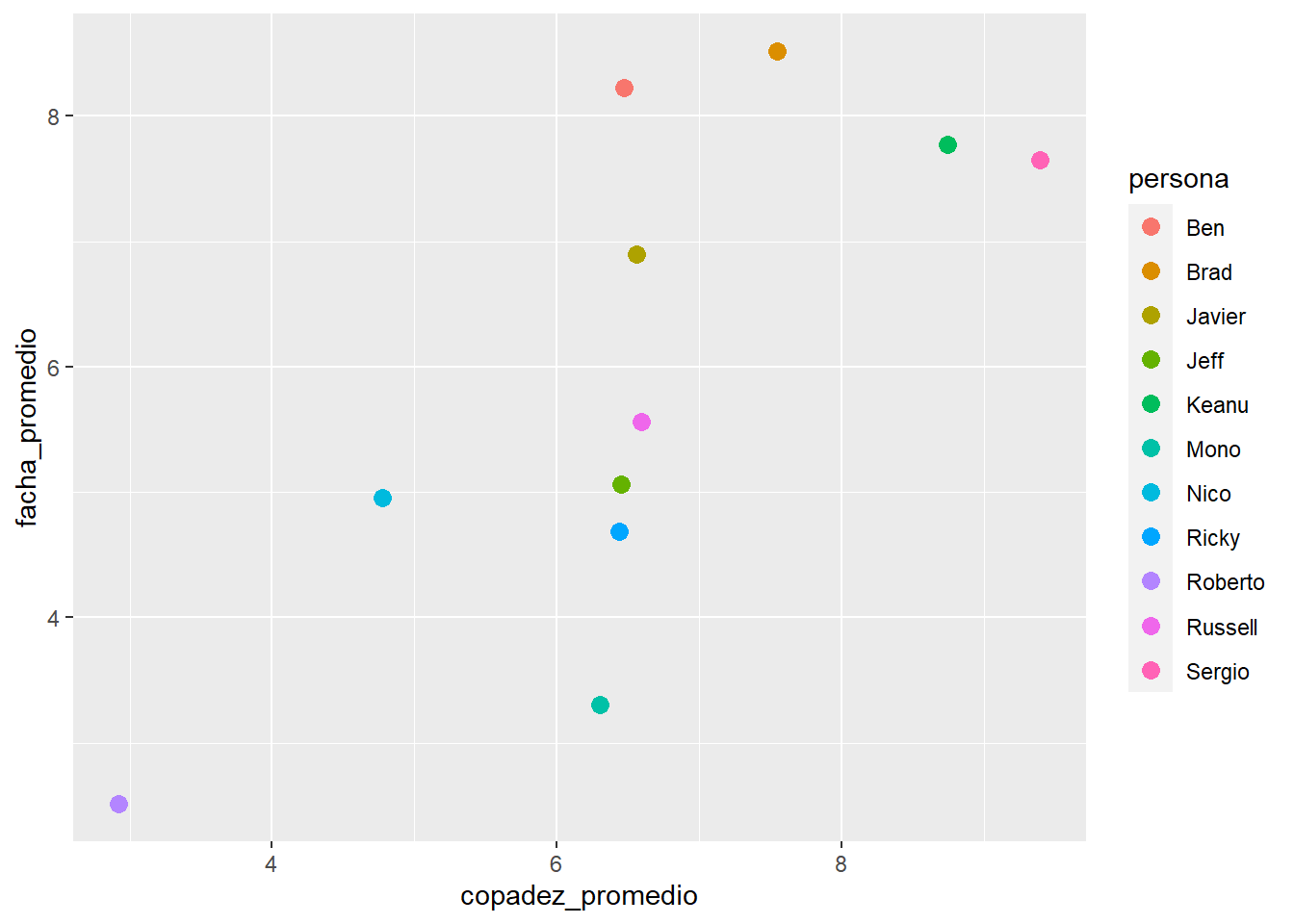
# Calculamos los resultados promedios para cada persona y graficamos los resultadosresultados <- clones %>%group_by(persona) %>%summarise(facha_promedio =mean(Facha),copadez_promedio =mean(Copadez))ggplot(resultados, aes(x = copadez_promedio, y = facha_promedio, color = persona)) +geom_point(size =3)
En esencia, este es el gráfico al que queremos llegar. Así como está es medio aburrido, así que vamos a enchular este gráfico con imágenes.
Trabajando con las imágenes
Como contaba antes, primero armé una presentación en Canva y pegué todas las imágenes de cada personaje para que queden más o menos del mismo tamaño. Luego guardé cada imagen en un archivo separado, y en este caso las guardé en una carpeta que se llama clones.
Podría haber hecho la carga de las fotos una por una, pero quería hacer este trabajo lo más eficiente posible tratando de repetir pasos. Para eso tenemos que crear un data frame que tenga por un lado el nombre de la persona tal cual lo tenemos en la tabla de las votaciones, y que incluya la dirección a la imagen.
# Creamos un vector con los nombres de las personaspersona <- resultados %>%select(persona) %>%pull()# Creo un vector de imágenesruta <-"pics"# Ruta de las fotosextension <-"png"# Extensión de los archivos de imágenes# nombres de los archivosimagen <-c("Ben", "Brad", "Javier", "jeff", "keanu", "mono", "nico", "ricky", "roberto", "russell", "sergio")# Creo el vector de fotos con dirección y extensión completafoto <-str_c(ruta, imagen, sep ="/")foto <-str_c(foto, extension, sep =".")# Creo el dataframe y lo agrego al dataframe resultadospics <-data.frame(persona, foto)# Ver el resultado de este procesopics
persona foto
1 Ben pics/Ben.png
2 Brad pics/Brad.png
3 Javier pics/Javier.png
4 Jeff pics/jeff.png
5 Keanu pics/keanu.png
6 Mono pics/mono.png
7 Nico pics/nico.png
8 Ricky pics/ricky.png
9 Roberto pics/roberto.png
10 Russell pics/russell.png
11 Sergio pics/sergio.png
Ahora tenemos un data frame de 11 filas y dos columnas, con el nombre de cada persona, y la dirección al archivo que contiene las imágenes de cada una. Estos datos lo podemos integrar al data frame que veníamos trabajando con los resultados de Facha y Copadez promedio de cada personaje.
# Unimos los datasetsresultados <-left_join(resultados, pics)head(resultados)
# A tibble: 6 × 4
persona facha_promedio copadez_promedio foto
<chr> <dbl> <dbl> <chr>
1 Ben 8.23 6.47 pics/Ben.png
2 Brad 8.52 7.55 pics/Brad.png
3 Javier 6.89 6.56 pics/Javier.png
4 Jeff 5.06 6.45 pics/jeff.png
5 Keanu 7.77 8.74 pics/keanu.png
6 Mono 3.30 6.30 pics/mono.png
Poniendo imágenes al gráfico
Y ahora si, a lo que venimos: incluir las fotos en el gráfico
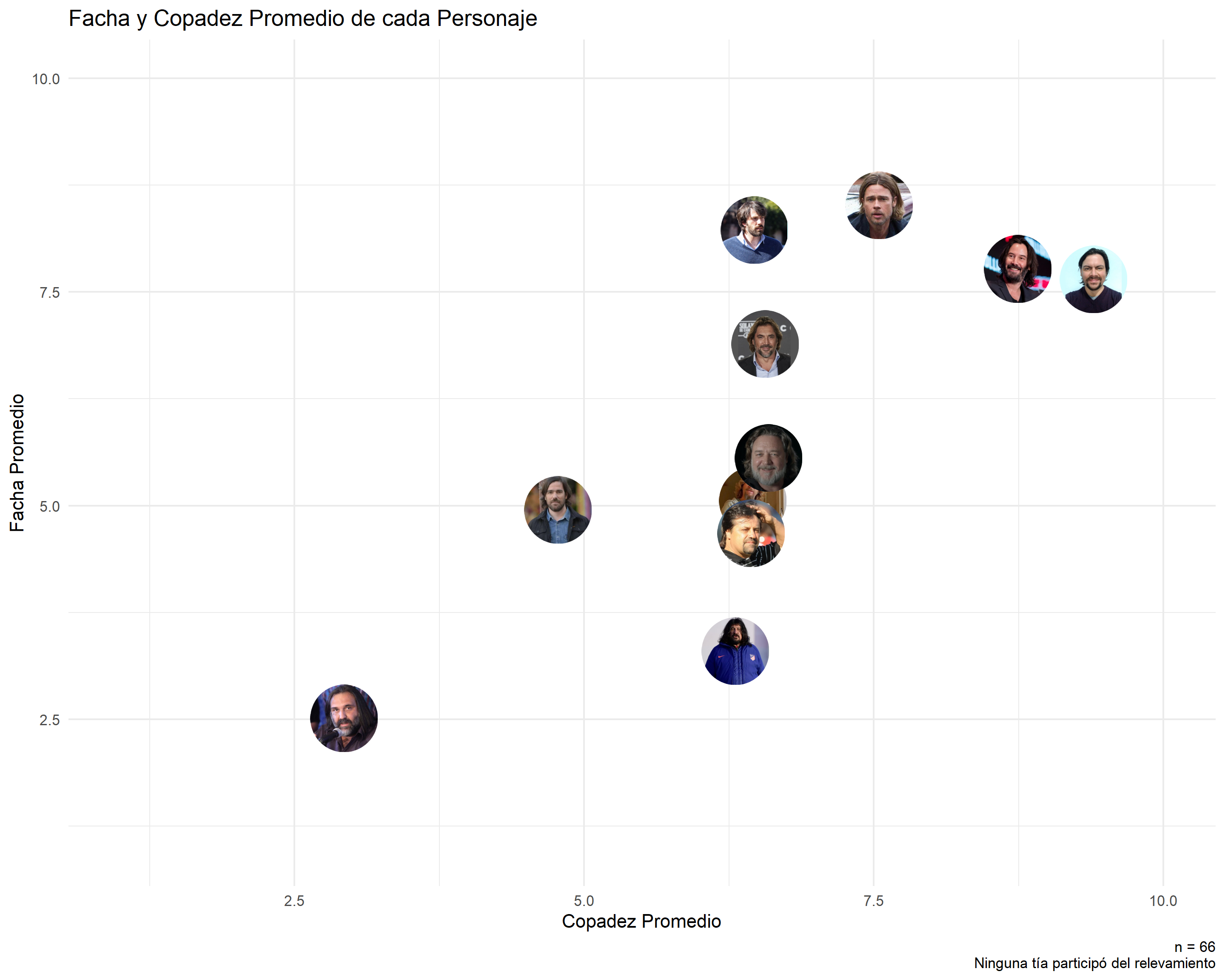
# El gráfico finalggplot(resultados, aes(x = copadez_promedio, y = facha_promedio)) +geom_image(aes(image=foto), size =0.08) +theme_minimal() +scale_x_continuous(limits =c(1,10)) +scale_y_continuous(limits =c(1,10)) +labs(title ="Facha y Copadez Promedio de cada Personaje",x ="Copadez Promedio", y ="Facha Promedio",caption ="n = 66\nNinguna tía participó del relevamiento")
Como conclusión del análisis los datos dicen que estoy alejado de las características de Nicolás del Caño y Roberto Baradel por ejemplo y tengo características muy similares que Keanu Reeves. O sea que los datos indican que me parezco a Keanu. Dato, no opinión 😎.
¿Qué saqué de todo esto?
En primer lugar aprender a usar un paquete nuevo, ggimage que permite incluir imágenes en los gráficos. Por otro lado hubo un error en el diseño del formulario (poner “Facha del Mono”) lo que implicó un paso extra en la limpieza de los datos. Ese error en este proyecto me ayudó a prevenir un potencial problema con una encuesta de diversidad para un cliente.
Otro tema fue la manipulación de los datos, pivotearlos de un formato “ancho” a uno “largo” y después nuevamente a uno “ancho” otra vez. Una vez que logré eso el cálculo de los resultados salió de manera muy simple.
Todo esto llevó dos días de trabajo, mirar tutoriales y documentación y mucha prueba y error. La verdad es que fue mucho trabajo, pero el hecho de ser un proyecto medio delirante le sacó mucha presión y me dió la motivación para aprender algo nuevo y superar las barreras y errores que me fui encontrando. Creo que el hecho que sea un proyecto divertido me liberó para tratar interpretar los mensajes de error y buscar la solución apropiada.
Este tipo de proyecto me parece ideal para realizar apenas terminás un tutorial o un curso. Los datos que usamos en un tutorial siempre están bastante limpios, controlados, divinos y cuando trabajás con tus propios datos te encontrás con barreras. Realizar este tipo de análisis sin la presión de “agregar valor” al negocio y pone a prueba las habilidades que tenés.
Así que te invito a que hagas un proyecto ridículo y que lo compartas con el mundo.
Final
Si querés ver el script final de este post, lo podés encontrar en el repositorio en este link.
Y como regalo final, me reí mucho con los comentarios que hicieron las personas que participaron del relevamiento de datos así que los comparto con ustedes:
Comentarios
te rompí los patrones a la merd
jaja me rei mucho!
Caruso a la Final!
Johnny Depp, 8/8
Hajajja
De Brad Pitt te copiaste el peinado, no?
¿es requisito tener pelo largo para parecer fachero? mostrame indicadores
Sergio vos no estas bien haciendo esto!!! Jajaja
Falta Denicolay
Jajaj muy bueno
Haces todo esto para levantarte minas Mora, lo sabemos!!!
ME ENCANTÓ! curiosa, dinámica y original iniciativa como siempre!!
Copado el test!!
¿todos hombres?
Hajajja
WTH??
Sos un capo!!! me divertí mucho!!!
Falta el test de mujeres.....
Bronn, de game of thrones.
Muy buen ejercicio! A algunos personajes el 1 le quedaba grande! habiliten el 0 jaja Éxitos!
Un genio Sergio 😂😂😂 Podría ser también a la versión adulta del niño del sexto sentido, el que dice"veo gente muerta" ¿? 🤔
Puedo decir que la foto que te sacaste, es muy de MA de instagram
Jaja me hiciste reír. Cómo no soy de Argentina tuve que googlear algunos, pero todo bien. Super entretenido