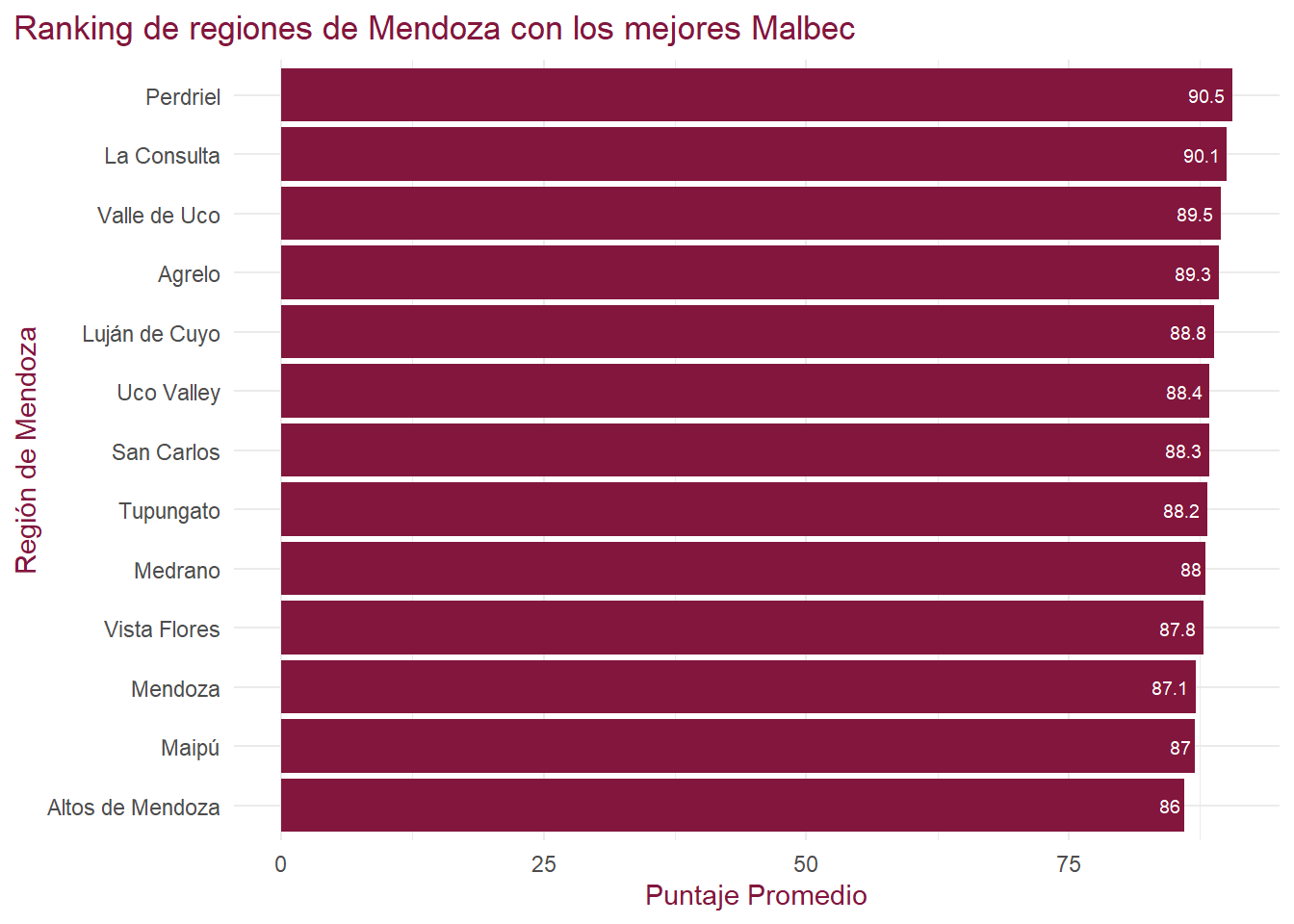
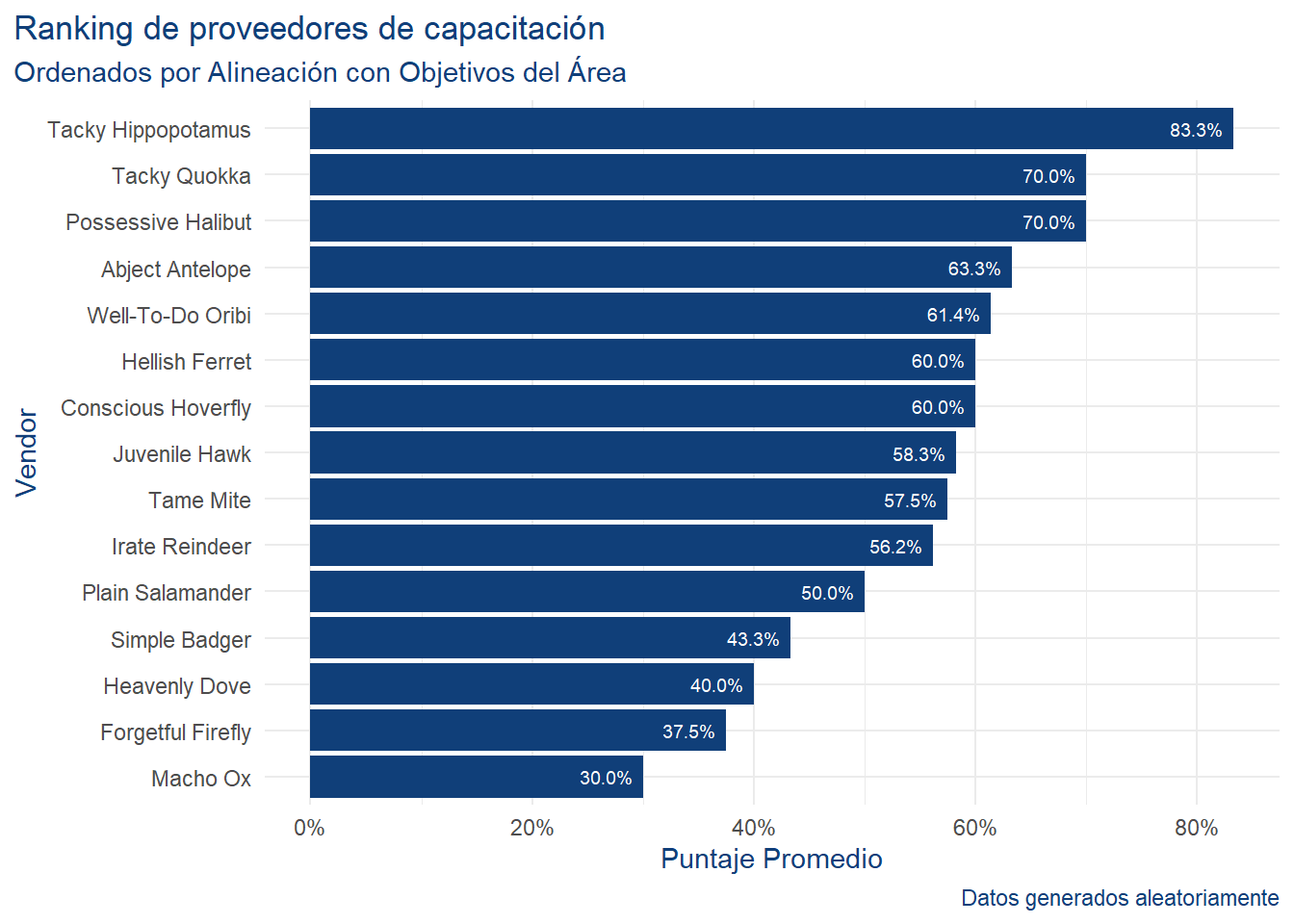
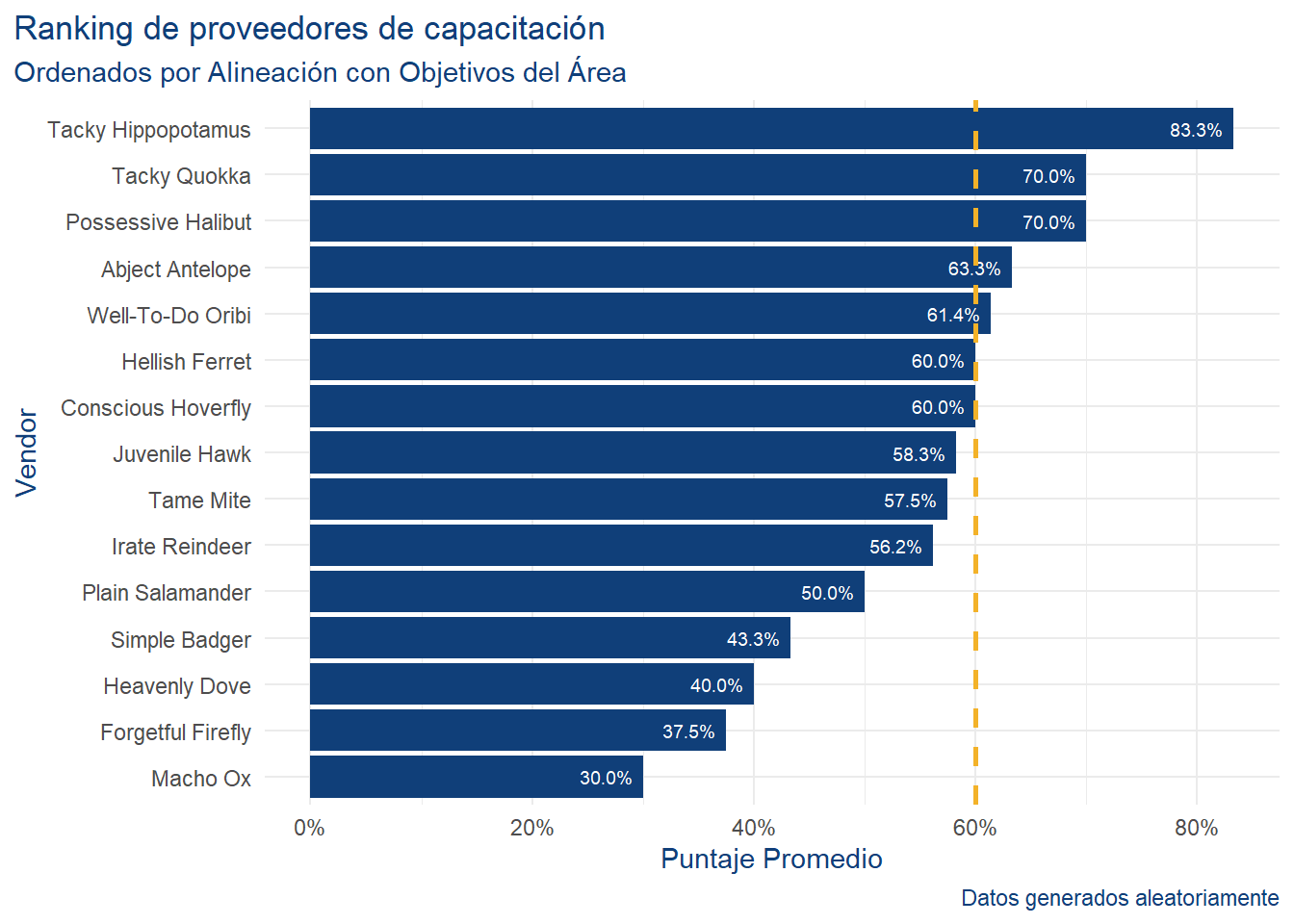
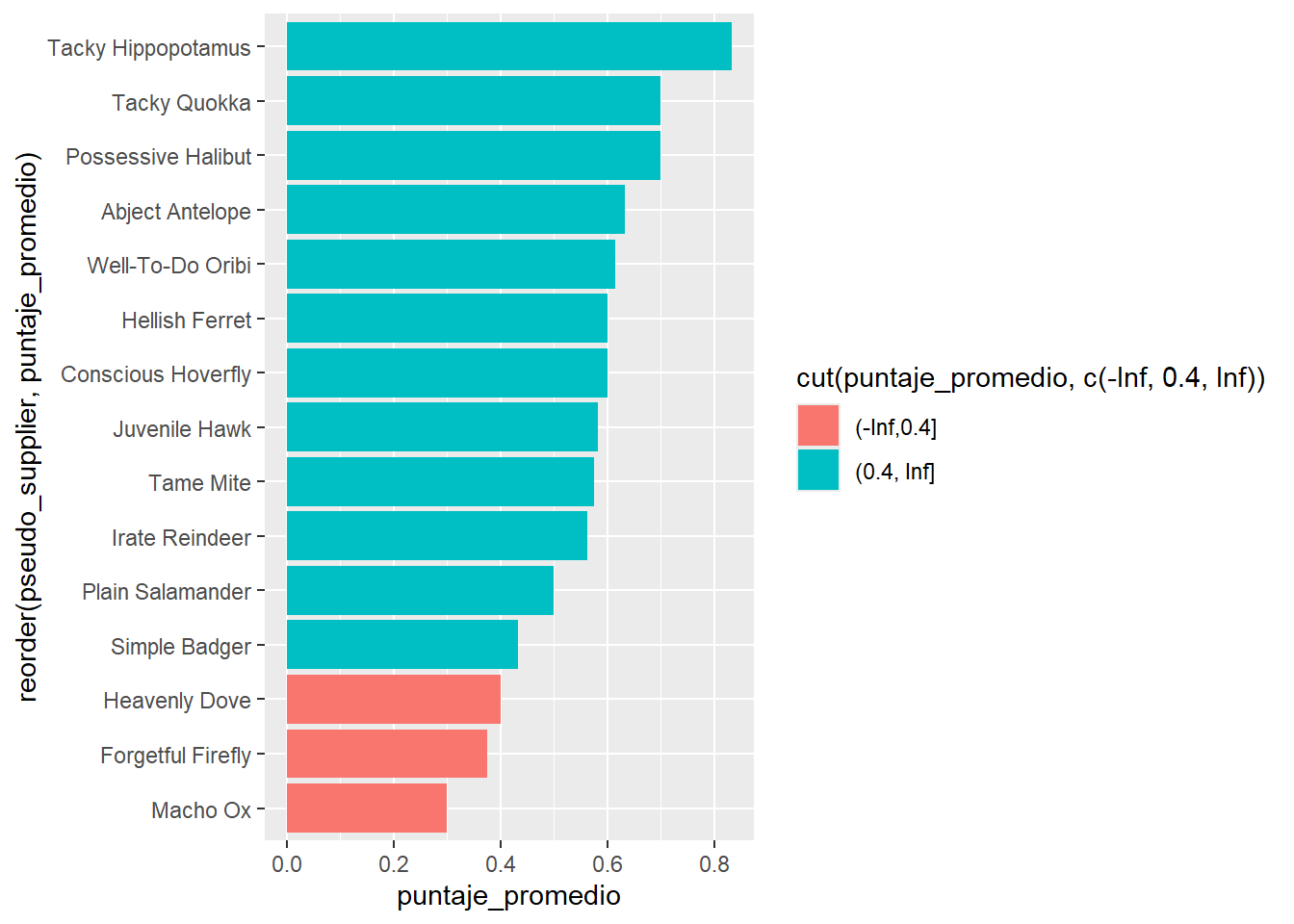
Rows: 101
Columns: 11
$ id_training <dbl> 129, 129, 129, 129, 145, 41, 41, 41, 41, 41, 41…
$ program <chr> "5 por qué/ Problem Solving", "5 por qué/ Probl…
$ id_emp <dbl> 892, 898, 1499, 1695, 967, 804, 879, 1454, 1455…
$ satisfaction <dbl> 8, 7, 2, 5, 6, 10, 5, 9, 8, 4, 2, 8, 6, 10, 8, …
$ facilitator_score <dbl> 4, 2, 8, 10, 10, 6, 6, 7, 4, 7, 1, 10, 6, 8, 4,…
$ materials_satisfaction <dbl> 8, 9, 5, 9, 9, 7, 4, 1, 1, 8, 5, 1, 9, 7, 1, 9,…
$ willing_reccomend <dbl> 8, 7, 8, 1, 4, 5, 1, 2, 10, 8, 7, 8, 5, 5, 5, 9…
$ area_goals_alignment <dbl> 0.4, 0.5, 0.9, 0.6, 0.4, 0.1, 0.6, 0.5, 0.6, 0.…
$ work_aplication <dbl> 1.0, 0.6, 0.4, 0.9, 0.9, 0.1, 0.8, 0.1, 0.3, 0.…
$ scrap_learning <dbl> 0.0, 0.4, 0.6, 0.1, 0.1, 0.9, 0.2, 0.9, 0.7, 0.…
$ supplier <chr> "INTERNO", "INTERNO", "INTERNO", "INTERNO", "IN…